El proceso de normalización de bases de datos consiste en designar y aplicar una serie de reglas a las relaciones obtenidas tras el paso del modelo entidad-relación al modelo relacional.
Las bases de datos relacionales se normalizan para:
- Evitar la redundancia de los datos.
- Disminuir problemas de actualización de los datos en las tablas.
- Proteger la integridad de los datos.
En el modelo relacional es frecuente llamar tabla a una relación, aunque para que una tabla sea considerada como una relación tiene que cumplir con algunas restricciones:
- Cada tabla debe tener su nombre único.
- No puede haber dos filas iguales. No se permiten los duplicados.
- Todos los datos en una columna deben ser del mismo tipo.
Los términos Relación, Tupla y Atributo derivan del álgebra y cálculo relacional, que constituyen la fuente teórica del modelo de base de datos relacional.
Todo atributo en una tabla tiene un dominio, el cual representa el conjunto de valores que el mismo puede tomar. Una instancia de una tabla puede verse entonces como un subconjunto del producto cartesiano entre los dominios de los atributos. Sin embargo, suele haber algunas diferencias con la analogía matemática, ya que algunos RDBMS permiten filas duplicadas, entre otras cosas. Finalmente, una tupla puede razonarse matemáticamente como un elemento del producto cartesiano entre los dominios.
Primera Forma Normal (1FN)
Una tabla está en Primera Forma Normal si:
- Todos los atributos son atómicos. Un atributo es atómico si los elementos del dominio son simples e indivisibles.
- La tabla contiene una clave primaria única.
- La clave primaria no contiene atributos nulos.
- No debe existir variación en el número de columnas.
- Los Campos no clave deben identificarse por la clave (Dependencia Funcional)
- Debe Existir una independencia del orden tanto de las filas como de las columnas, es decir, si los datos cambian de orden no deben cambiar sus significados
Esta forma normal elimina los valores repetidos dentro de una Base de Datos.
Segunda Forma Normal (2FN)
Dependencia Funcional. Una relación está en 2FN si está en 1FN y si los atributos que no forman parte de ninguna clave dependen de forma completa de la clave principal. Es decir que no existen dependencias parciales. (Todos los atributos que no son clave principal deben depender únicamente de la clave principal). Por ejemplo {DNI, ID_PROYECTO} 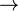 HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto sabemos cuántas horas de trabajo por semana trabaja un empleado en dicho proyecto) es completamente funcional dado que ni DNI HORAS_TRABAJO ni ID_PROYECTO HORAS_TRABAJO mantienen la dependencia. Sin embargo {DNI, ID_PROYECTO} NOMBRE_EMPLEADO es parcialmente dependiente dado que DNI NOMBRE_EMPLEADO mantiene la dependencia.
HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto sabemos cuántas horas de trabajo por semana trabaja un empleado en dicho proyecto) es completamente funcional dado que ni DNI HORAS_TRABAJO ni ID_PROYECTO HORAS_TRABAJO mantienen la dependencia. Sin embargo {DNI, ID_PROYECTO} NOMBRE_EMPLEADO es parcialmente dependiente dado que DNI NOMBRE_EMPLEADO mantiene la dependencia.
HORAS_TRABAJO (con el DNI de un empleado y el ID de un proyecto sabemos cuántas horas de trabajo por semana trabaja un empleado en dicho proyecto) es completamente funcional dado que ni DNI HORAS_TRABAJO ni ID_PROYECTO HORAS_TRABAJO mantienen la dependencia. Sin embargo {DNI, ID_PROYECTO} NOMBRE_EMPLEADO es parcialmente dependiente dado que DNI NOMBRE_EMPLEADO mantiene la dependencia.Tercera Forma Normal (3FN)
La tabla se encuentra en 3FN si es 2FN y si no existe ninguna dependencia funcional transitiva entre los atributos que no son clave.
Un ejemplo de este concepto sería que, una dependencia funcional X->Y en un esquema de relación R es una dependencia transitiva si hay un conjunto de atributos Z que no es un subconjunto de alguna clave de R, donde se mantiene X->Z y Z->Y.
Por ejemplo, la dependencia SSN->DMGRSSN es una dependencia transitiva en EMP_DEPT de la siguiente figura. Decimos que la dependencia de DMGRSSN el atributo clave SSN es transitiva vía DNUMBER porque las dependencias SSN→DNUMBER y DNUMBER→DMGRSSN son mantenidas, y DNUMBER no es un subconjunto de la clave de EMP_DEPT. Intuitivamente, podemos ver que la dependencia de DMGRSSN sobre DNUMBER es indeseable en EMP_DEPT dado que DNUMBER no es una clave de EMP_DEPT.
Estas tres son las que más vamos a utilizar ya que con estos 3 pasos por así decirlo ya tendriamos una base de datos funcional al 99.9% :3

